I detta dokument har vi börjat med en kortare inblick i vad maskininglärning är, var i ekosystemet av datavetenskap det hör hemma samt börjat titta på skillnaden mellan maskininlärning och traditionell mjukvaruutveckling. Vi har presenterat varför maskininlärning har blivit populärt nyligen, d.v.s vad som möjliggjort konkreta implementationer och vi har också gjort en kort introduktion till varför vi bör vara extra uppmärksamma i vår problemanalys som en effekt av detta.
Innan vi berättar om maskininlärningens fördelar kan det vara bra att sätta saker i perspektiv för att se varför maskininlärning har fått mycket fokus de senaste åren. Om man baserar sina referenspunkter på rådande mediebild för maskininlärning är det enkelt att tro att hela verktygslådan är ny. Många av de teoretiska byggstenar som behövs för maskininlärning har en gedigen historia. Det är den tekniska mognaden, snarare än nya algoritmer, som nyligen har uppkommit. Därför kommer här ett handplock av viktiga byggstenar som förklarar vad det är som gör det möjligt med maskininlärning just nu.
Maskininlärning idag – varför nu?
Det finns inom maskininlärning en teoretisk grund som har rötter inom matematiken. Det kan vara bra att hålla den teoretiska utvecklingen separat från vad som idag i praktiken går att genomföra. Det som tekniskt har möjliggjort maskininlärning idag är huvudsakligen följande aspekter:
Så kallad Big Data gör det möjligt att använda algoritmer som bygger en modell av problemet genom att titta på väldigt många exempel och på så vis lära sig mönster. Genom att observera stora datavolymer går det att bygga en statisk modell över problemet. Antalet system som har en datamängd som behövs för att bygga en bra statistisk modell har blivit allt vanligare de senaste tio åren.
Allt bättre beräkningskraft möjliggör att stora datavolymer kan bearbetas. Det räcker inte att lagra stora datavolymer om det inte går att processera dem genom de algoritmer som maskininlärning kräver. Molntjänster som exempelvis Amazon Web Services (AWS) gör det enkelt att få tillgång till de fysiska resurserna som krävs utan att konsumenten själv behöver administrera hårdvaran; vilket öppnar upp marknaden även för aktörer som inte har den ekonomiska möjligheten att administrera serverkluster själva.
Den tekniska mognadentillsammans med en alltmer utvecklad verktygslåda av självlärande algoritmerär en kombination som gör att vi nu står i startgroparna för framtiden inom maskininlärning. Även på ett teoretisk plan är det ännu mycket som är oklart. När industrin nu börjar bygga system som baseras på självlärande algoritmer har det öppnat upp ett stort outforskat område av problem som tidigare inte kunnat lösas av datorer.
Kort Historik
År 1847 skrev Louis Augustin Cauchy sin artikel Compte Rendu ‘a l’Academie des Sciences om icke-linjära gradienta metoder för optimeringsproblem, en idag självklar byggsten inom maskininlärning.
Modellen om hur ett neuralt nätverk fungerar presenterades av Warren McCulloch och matematikern Walter Pittsredan år 1943. Tätt därpå, år 1949, skrev Donald Hebb sin artikel The Organization of Behavior som presenterade en viktig aspekt av att neuroners banor stärks om de avfyras samtidigt. Detta blev en publikation av hur lärande kan modelleras teoretiskt.
För att jämföra teori och praktik kan vi se ungefär var datavetenskapen befann sig på 40-talet. Electronic Numerical Integrator And Computer (ENIAC) var en av de första, men inte den enda, turingkompletta programmerbara datorerna vid denna tiden. ENIAC byggdes på Univerity of Pensylvania år 1946, finansierat av staten, och det huvudsakliga syftet var att räkna ut projektilbanor. Det som tog en människa 20 timmar, kunde nu ENIAC göra på 30 sekunder.
På 50 och 60-talet hände mycket med forskningen inom optimeringsproblem. Algoritmen Stocastic gradient descent blev djupare utforskat och många viktiga byggstenar publicerades; Robbins och Monro A Stochastic Approximation Method och Kiefer och Wolfowitz Stochastic Estimation of the Maximum of a Regression Function för att nämna några.
Som tidigare presenterats går det att se hur de teoretiska modellerna långt föregick de tekniska förmågorna med datum som sträcker sig tillbaka till 1800-talet. Länge ansågs gradienta modeller också problematiska ur en teoretisk och matematisk synvinkel eftersom det inte finns garantier att den optimala lösningen hittas.
Vad är maskininlärning
För att beskriva vad maskininlärning är börjar vi med att presentera en överblick. Inom området datavetenskap finns ett överlapp mellan mjukvaruutveckling, matematik och statistik och domänexpertis.

Figur 1: Datavetenskap
Området datavetenskap kan kategoriseras som i fig 2. I området mjukvaruutveckling ser vi det traditionella hantverket med att programmera, driftsätta och underhålla ett system. I överlappet mellan matematik och statistik kan vi se hur maskininlärning tar sin plats i ekosystemet. Det som gör maskininlärning komplext är just överlappet mellan praktiska uppgifter av mjukvaruutveckling och det teoretiska området matematik och statistik. Den sista biten är domänexpertis. I ett företag som driver en enskild produkt finns domänkompetensen, eller branchkunskapen, inom företaget d.v.s företag som är experter på problemet deras produkt löser. I andra företag, såsom ett konsultföretag, behöver expertisen komma från kunden.
Det som skiljer traditionell utveckling från maskininlärning är hur systemet byggs för att följa uppsatta regler. Inom traditionell utveckling behöver utvecklaren explicit definiera varje beslut systemet kan ta och vad resultatet av den givna inputen är. Oavsett hur många gånger en given situation händer kommer systemet alltid göra exakt det den är programmerat till. En maskininlärd modell, som är tränad på data från domänen, kommer istället att lära sig dessa regler. Fördelen med en maskininlärd modell är att den kan lära sig komplexa regler och situationer utan att utvecklaren explicit behöver programmera varje regel. En modell innehåller vikter som definierar hur mycket betoning som ska läggas på olika typer av data. När en modell ser data med en stor vikt kommer den att uppfatta detta som viktigare för problemet som ska lösas. Att träna en modell innebär att hitta värdena på dessa vikter genom att observera många tidigare exempel och korrigera vikterna. En modell lär sig traditionellt sätt vikternas värde i tre steg.
- Modellen initieras med slumpmässiga vikter och utför en kvalificerad gissning eller hypotes.
- Hypotesen som modellen skapat rättas mot det korrekta resultatet.
- Efter rättningen korrigeras modellens vikter beroende på hur korrekt hypotesen var. I varje iteration mäter man träffsäkerheten på modellen och slutar träna när all data används eller när modellens träffsäkerhet börjar bli sämre.
Detta är givetvis en grov förenkling av processen och beskriver det man brukar kalla supervised learning. Vi kommer dyka djupare in hur detta i realiteten går till senare. Det som bör uppmärksammas är skillnaden mellan hur regler explicit måste definieras i traditionell utveckling och hur en maskininlärd modell kan ses mer som en svart låda som ges data och själv klurar ut reglerna.
Utmaningen att hitta rätt kompetens och data
De huvudsakliga resurserna är idag kompetens och data. I vanlig bemärkelse behövs det ett slipat team med bra projektledning, utrymme för kreativitet och initiativtagande samt ödmjukhet för sina egna kompetenser. Detta är inte på något vis unikt för just maskininlärningsprojekt och kommer därför inte heller avhandlas ytterligare.
Att hitta personer som är skickliga inom mjukvaruutveckling och matematik och statistik kan vara svårt. Ofta är det extra svårt att hitta folk med kompetens inom både mjukvaruutveckling och matematik/statistik. I praktiken behöver kompetensen innehas av samma fysiska person i motsats till två personer som bildar rollen. Därför blir också det första naturliga steget att hitta personer med kompetens inom maskininlärning.
När kompetens finns tillgänglig är det lätt att dessa nyckelpersoner blir en flaskhals för organisationen. Det är inte omöjligt att det står tio projekt för dörren och väntar på en person som kan maskininlärning. Det spelar heller ingen roll hur mycket kompetens som finns om inte tid avsätts för att genomföra projektet inom en rimlig tidsplan. Därför kan det istället vara bättre att köpa in konsulter som genomför dessa uppgifter.
För att bygga en tränad modell av problemet behövs data. Generellt sätt kan sägas att ju mer data desto bättre. Det är också viktigt att den data som finns är statistiskt signifikant, d.v.s. innehåller data som omfattar problemet som ska lösas. Till exempel går det inte kan bygga en maskininlärd regnprognosmodell om datan modellen är tränad på inte innehåller exempel på dagar utan regn och dagar med regn. Obalans i datan spelar också stor roll. Om det är väldigt få exempel med dagar som är regniga kommer det behövas mer data för att träna modellen.
Den sista pusselbiten är domänexpertis. Detta innefattar oftast kompetens hos kunden. Samma förhållande angående tid gäller även här när vi försöker hitta personer med kompetens inom den specifika domänen som har tid. Låt oss tänka ett scenario där det ska byggas ett klassificeringsystem för cancer. Då krävs det att kunden tillhandahåller kompetens som kan avsätta tid för att förklara hur domänen, i detta fallet cancervården, fungerar. Är det till exempel bättre att säga att fler personer har cancer än de i själva verket har eller hur ska vi resonera i de gränsfall där vår modellen inte är särskilt säker? Denna domänexpertis måste finnas tillgänglig för ett genomförbart projekt eftersom vissa beslut inte kan tas av personen som skriver koden.
Undvik hypen
Eftersom maskininlärning är ett brett område är det viktigt att rätt frågor ställs. I ett scenario där fel frågor ställs spelar det ingen roll hur bra modeller som byggs eftersom modellerna kommer svara på en fråga som irrelevant.
När du har en hammare ser allt ut som en spik.
För att rätt frågor ska ställas krävs en noggrann analys av problemet. Det finns ingen syfte att utföra maskininlärning om det inte är det bästa verktyget för att lösa ett problem. För att skapa en bättre problemanalys vill vi därför presentera följande bild som illustrerar livscykeln för ny teknik.
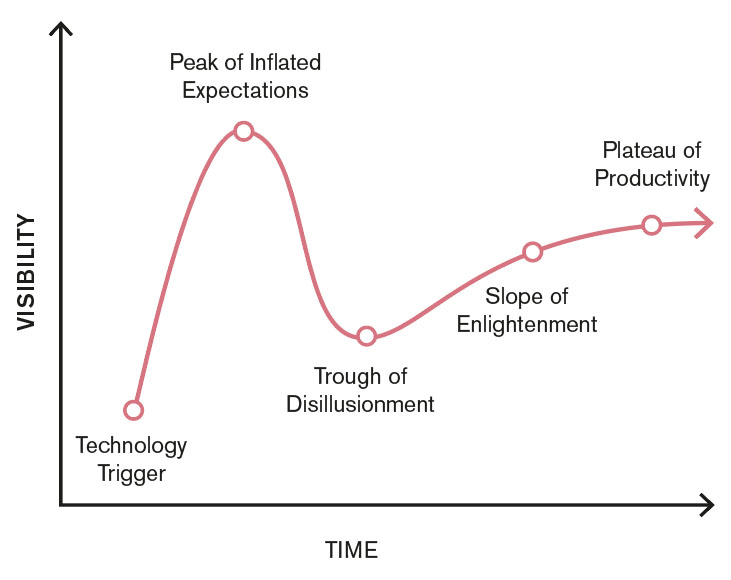
Figur 3: Uppblåsta förväntningar. Förslag på översättningar av namn: Teknology trigger, Toppen av uppblåsta förväntningar, botten av totalt avslöjande, gradvis insikt, platån av produktivitet.
Just nu befinner sig maskininlärning i uppförsbacke där vi ännu inte nått “toppen av uppblåsta förväntningar”. För att få en bättre problemanalys bör detta tas i åtanke så att rätt verktyg används för rätt problem. Vi kommer återkomma till detta diagrammet senare i artikelserien och se hur detta relaterar till den typen av verksamhet som omfattar maskininlärning och hur vi behöver vara vaksamma så att arbetet som utförs är konstruktivt. I de kommande dokumenten kommer vi dyka in djupare i riktiga användarfall, se en mer konkret bild av processen av ett maskininlärningsprojekt och visa var fokus bör ligga för att öka chanserna för ett meningsfullt projekt.