In this document we will start with a shorter insight into what machine learning is, where in the ecosystem of computer science it belongs and looks at the difference between machine learning and traditional software development. We will present why machine learning has become popular recently, that is, what enabled concrete implementations, and we will also make a brief introduction to why we should pay extra attention to our problem analysis as an effect of this.
Machine Learning Today
Before we talk about the advantages of machine learning, it may be good to put things in perspective to see why machine learning has gained a lot of focus in recent years. If you base your reference points on the current media image for machine learning, it is easy to believe that the entire toolbox is new. Many of the theoretical building blocks needed for machine learning have a solid history. It is the technical maturity, rather than the new algorithms that have recently emerged. Therefore, we will now outline some of the important building blocks that explain why machine learning is possible right now.
Why Now?
There is a theoretical foundation in machine learning that has roots in mathematics. It may be good to keep the theoretical development separate from what is practically possible today. What has technically enabled machine learning today is mainly the following aspects:
Large data volumes, so-called Big Data makes it possible to use algorithms that build a model of the problem at many examples and thus learning patterns. By observing large data volumes, it is possible to build a static model of the problem. The number of systems that have a data set needed to build a good statistical model has become more common in the last ten years.
Increasing computational power enables large data volumes to be processed. It is not enough to store large data volumes if it cannot be processed by the algorithms that machine learning requires. Cloud services such as Amazon Web Services (AWS) make it easy to access the physical resources required without having to administer the hardware itself; which also opens up the market for operators who do not have the financial opportunity to administer server clusters themselves.
The technical maturity together with an increasingly developed toolbox or self-learning algorithms is a combination, which means we are now at the forefront of the future in machine learning. Even on a theoretical level, much is still unclear. With the industry now beginning to build systems based on self-learning algorithms, it has opened up a large, unexplored area of problems that could not be solved by computers.
Short History
In 1847, Louis Augustin Cauchy wrote his article on the Academy of Sciences on non-linear gradient methods for optimization problems, a current self-evident building block in machine learning.
The model of how a neural network works was presented by Warren McCulloch and mathematician Walter Pittsa as early as 1943. Close thereafter, in 1949, Donald Hebb wrote his article “The Organisation of Behaviour” which presented an important aspect of strengthening neuron pathways if fired simultaneously. This became a publication of how learning can be modelled theoretically.
To compare theory and practice, we can see where computer science was in the 40s. Electronic Numerical Integrator And Computer (ENIAC) was one of the first, but not the only, complete computer programmable computers at this time. ENIAC was built at the University of Pennsylvania in 1946, financed by the state, and the main purpose was to calculate projectile tracks. What previously took 20 hours, ENIAC now could do in 30 seconds.
In the 50s and 60s, much was happening in research into optimisation problems. The stocastic gradient descent algorithm was explored deeper, and many important building blocks were published; Robbins and Monroc “A Stochastic Approximation Method” and Kiefer and Wolfowitzd “Stochastic Estimation of the Maximum of a Regression Function”, to name a few.
As previously presented, it is possible to see how the theoretical models far preceded the technical abilities with dates go back to the 19th century. For a long time, gradient models were also considered problematic from a theoretical and mathematical point of view because there are no guarantees that the optimal solution can be found.
What exactly is Machine Learning
To describe what machine learning is, we began by presenting an overview. In the area of computer science there is an overlap between software development, mathematics and statistics and domain expertise.
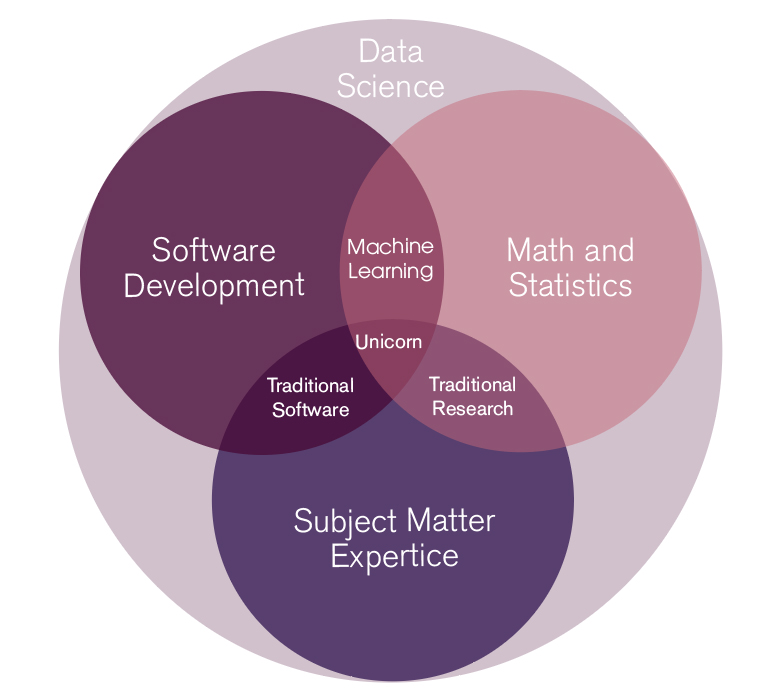
Fig 1. Data Science
The area of computer science can be categorised as in fig 2. In the area of software development we see the traditional craft of programming, commissioning and maintaining a system. In the overlap between mathematics and statistics, we can see how machine learning takes its place in the ecosystem. What makes machine learning complex is precisely the overlap between practical tasks of software development and the theoretical field of mathematics and statistics. The last bit is domain expertise. In a company that runs an individual product, the domain competence, or industry knowledge, is within the company, ie companies that are experts on the problem their product solves. In other companies, such as a consulting company, the expertise needs to come from the customer.
What distinguishes traditional development from machine learning is how the system is built to comply with established rules. In traditional development, the developer needs to explicitly define each decision the system can take and what the result of the given input is. No matter how many times a given situation happens, the system will always do exactly what it is programmed for. A machine-taught model, which is trained on data from the domain, will instead learn these rules. The advantage of a machine-taught model is that it can learn complex rules and situations without the developer having to explicitly program each rule. A model contains weights that define how much emphasis should be placed on different types of data. When a model sees data with great importance, it will perceive this as more important for the problem to be solved. Training a model involves finding the values of these weights by observing many previous examples and correcting the weights. A model traditionally learns the weight of the weights in three steps.
- The model is initiated with random weights and performs a qualified guess or hypothesis.
- The hypothesis that the model created is corrected against the correct result.
- After the correction, the weight of the model is corrected depending on how correct the hypothesis was. In each iteration one measures the accuracy of the model and stops training when all the data is used or when the model's accuracy begins to deteriorate.
This is, of course, a gross simplification of the process and describes what one usually calls supervised learning. We will delve deeper later how this works in reality. What should be noted is the difference between how rules must be explicitly defined in traditional development and how a machine-taught model can be seen more as a black box that is given data and makes the rules itself.
The challenge to find the right skills and data
The main resources today are competence and data. In the normal sense, a grounded team with good project management, space for creativity and initiative and humility is needed for their own competencies. This is in no way unique for just machine learning projects and will therefore not be further discussed.
Finding people who are skilled in software development and mathematics and statistics can be difficult. Often it is even more difficult to find people with competence in both software development and mathematics / statistics. In practice, the competencies needs to be held by the same person as opposed to two people who form the role. Therefore, the first natural step is to find people with competence in machine learning.
When skills are available, it is easy for these key people to become a bottleneck for the organisation. It is not unusual that there could be ten projects waiting for a person who can utilise machine learning. It also does not matter how much expertise exists if time is not set aside to implement the project within a reasonable timetable. Therefore, it may be better to buy in consultants who can carry out these tasks.
To build a trained model of the problem, data is needed. Generally speaking, the more data the better. It is also important that the data available is statistically significant, i.e. contains data that includes the problem to be solved. For example, it is not possible to build a machine-learned rain forecast model if the data model trained on does not include examples of days without rain and rainy days. The imbalance in the data also plays a major role. If there are very few examples with days that are rainy, more data will be needed to train the model.
The last piece of the puzzle is domain expertise. This usually includes the expertise of the customer. The same relationship regarding time also applies here when we try to find people with expertise in the specific domain that has time. Let's think of a scenario where a classification system for cancer is to be built. Then it requires the customer to provide expertise that can set aside time to explain how the domain, in this case the cancer care, works. For example, is it better to say that more people have cancer than they actually have or how should we reason in the border cases where our model is not particularly safe? This domain expertise must be available for a feasible project because some decisions cannot be taken by the person writing the code.
Avoid the hype
Since machine learning is a broad area, it is important that the right questions are asked. In a scenario where the wrong questions are asked, it doesn't matter how good the models are built because the models will answer a question as irrelevant.
When you have a hammer, everything looks like a nail.
In order for the right questions to be asked, a careful analysis of the problem is required. There is no benefit in performing machine learning unless it is the best tool to solve a problem. In order to create a better problem analysis, we therefore want to present the following picture that illustrates the life cycle of new technology.
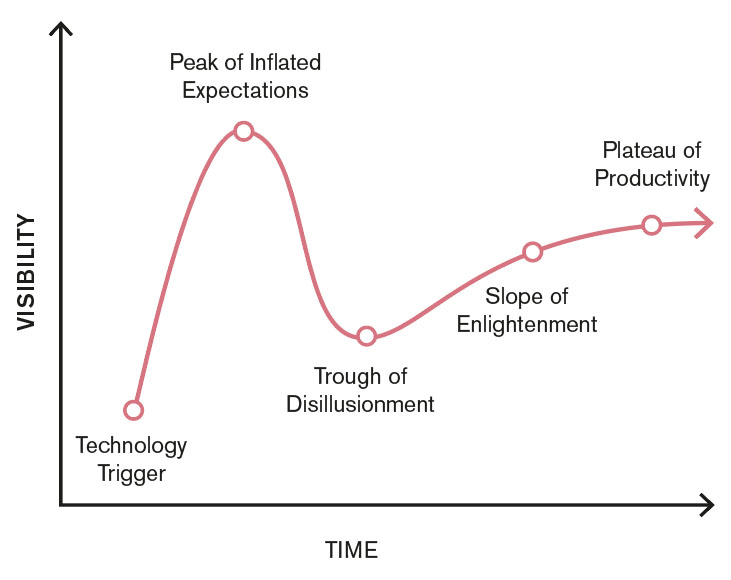
Figur 3:
Right now, machine learning is on an uphill trajectory where we have not yet reached the "peak of inflated expectations". To get a better problem analysis, this should be taken into consideration so that the right tool is used for the right problem. We will return to this chart later in the article series and see how this relates to the type of activity that involves machine learning and how we need to be vigilant so that the work being carried out is constructive. In the upcoming documents, we will deeper into real user cases, see a more concrete picture of the process of a machine learning project and show where the focus should be to increase the chances of a meaningful project.
Read the first part about Machine Learning
Victor Axelson
Developer at DING